Why predictive maintenance matters for blockchain networks
Predictive maintenance для блокчейн‑сетей звучит немного странно, пока не вспомнишь, что любая сеть — это кластеры нод, диски, каналы связи и куча сервисов, которые время от времени ломаются. Узкие места в пропускной способности, отваливающиеся валидаторы и перегретые базы данных приводят к задержкам транзакций и, в худшем случае, к форкам или простоям. Здесь на сцену выходят predictive maintenance blockchain solutions: они стараются не просто фиксировать аварию по логам, а заранее предсказывать, какая нода, участок сети или сервис вот‑вот уйдёт в отказ. Задача Auto‑ML — сделать этот процесс не только умным, но и максимально автоматизированным, чтобы команда не превращалась в отдел дата‑сайентистов.
Different approaches: from manual scripts to Auto‑ML
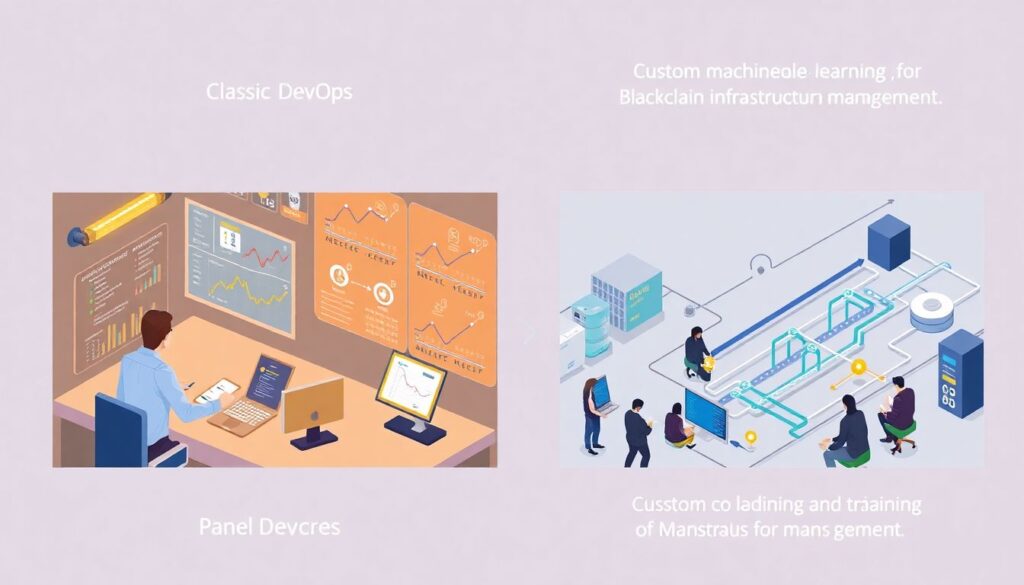
Если упростить картину, есть три основных подхода. Первый — классический DevOps: ручные алерты, дашборды, пороговые метрики. Дёшево и понятно, но почти не даёт предсказаний, только реакцию по факту. Второй — собственные модели machine learning for blockchain infrastructure management: команда собирает данные, пишет код, обучает модели аномалий или прогноза отказов. Гибко и мощно, но дорого по времени и кадрам. Третий путь — auto ml predictive maintenance platform: вы загружаете данные или подключаете стрим, платформа сама перебирает модели, выбирает лучшие и разворачивает пайплайны. Такой подход снижает порог входа и делает ML доступным даже небольшим командам, которые раньше ограничивались графиками в Grafana.
Necessary tools: что должно быть под рукой
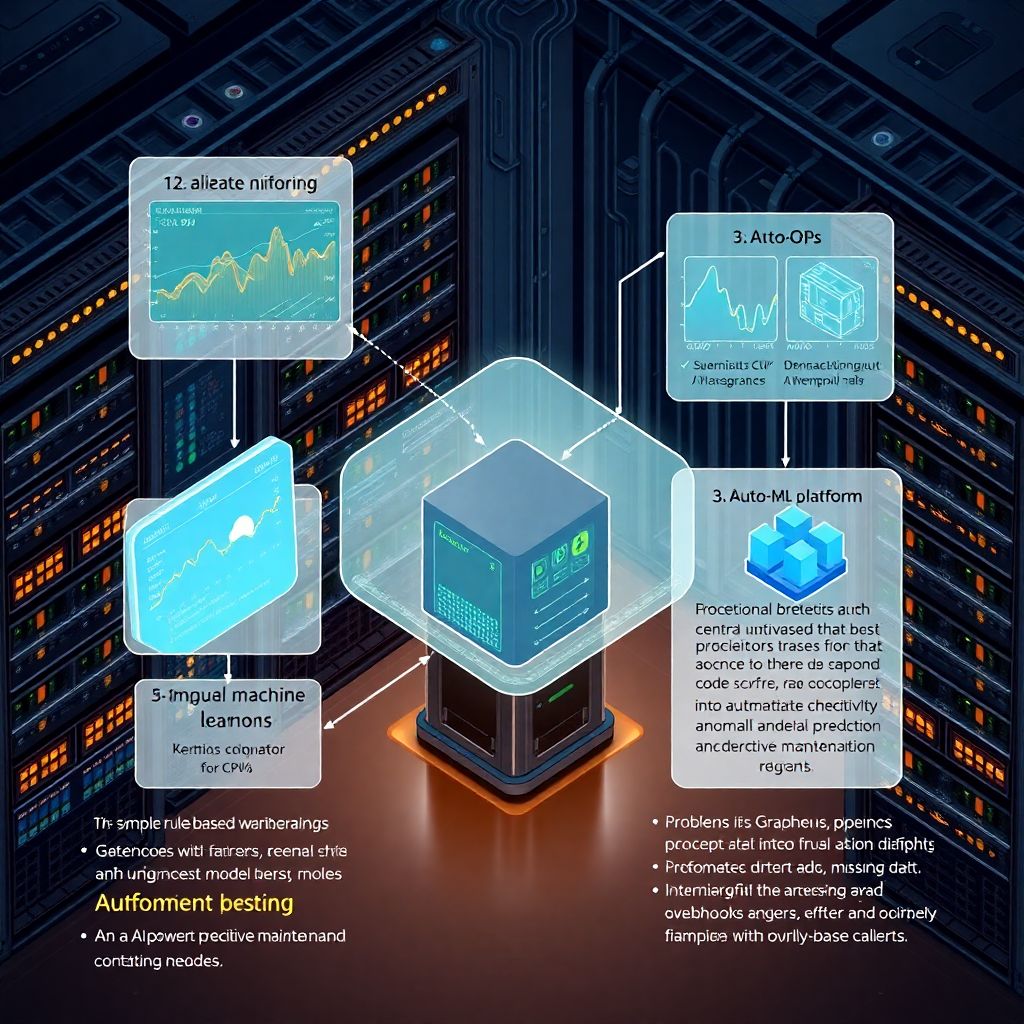
Чтобы вся эта история заработала, одной Auto‑ML‑кнопки мало. Нужен устойчивый контур сбора данных: логи нод, метрики аппаратуры, сетевые показатели, статус смарт‑контрактов и бизнес‑метрики (объём транзакций, латентность, частота ошибок). На этом слое лежат blockchain network monitoring and analytics tools — Prometheus, Loki, ELK‑стек, специализированные экспортёры для нод Ethereum, Cosmos, Substrate и т. п. Следующий уровень — ai powered predictive maintenance software или облачные AI‑сервисы, которые умеют забирать эти данные и строить модели. Плюс, конечно, хранилище (data lake / warehouse) и оркестрация (Airflow, Prefect или их аналоги), чтобы пайплайны обновлялись и не разваливались посреди ночи.
- Система мониторинга и логирования (метрики, логи, трейсы).
- Хранилище данных с историей работы нод и инфраструктуры.
- Auto‑ML или AI‑платформа с поддержкой табличных и временных рядов.
- Средства развёртывания моделей: API, batch‑воркеры, webhooks.
Step‑by‑step: как выглядит процесс с Auto‑ML
Практический цикл работы с Auto‑ML выглядит довольно приземлённо. Сначала вы определяете, что именно хотите предсказывать: вероятность падения ноды в ближайшие N часов, деградацию пропускной способности, рост латентности или вероятность «залипания» транзакций в мемпуле. Затем собираете исторические данные и метки: когда были инциденты, как выглядели метрики перед ними. Auto‑ML‑движок берёт этот датасет, делит на train/test, пробует разные алгоритмы, подбирает гиперпараметры и формирует рейтинг моделей. Важный момент — объяснимость: хорошие платформы сразу показывают важность признаков и дают возможность проверить модель на свежих инцидентах. После этого вы разворачиваете модель в прод, получаете прогнозы и связываете их с алертами в уже существующей системе мониторинга.
- Определить целевую задачу (классфикация отказов, прогноз нагрузки).
- Сформировать датасет: метрики, логи, события инцидентов.
- Запустить Auto‑ML, выбрать модель с лучшим балансом точности и стабильности.
- Интегрировать прогнозы в алертинг и операционные процессы.
- Периодически дообучать модель на новых инцидентах.
Manual ML vs Auto‑ML vs rule‑based: что реально работает
Если сравнивать подходы, rule‑based мониторинг выигрывает в прозрачности: любой инженер понимает, почему сработал алерт «CPU > 90% 5 минут». Но такие правила плохо ловят сложные, накопительные эффекты — например, сочетание слегка растущей латентности, редких ошибок в RPC и медленного увеличения размера state. Ручное ML‑решение даёт больше контроля и позволяет учитывать тонкости конкретного блокчейна, но требует серьёзной экспертизы и времени на поддержку. Auto‑ML же даёт золотую середину: он лучше видит многомерные паттерны, чем пороговые алерты, и дешевле по усилиям, чем полноценная ML‑команда. Однако за это приходится платить меньшей гибкостью тонкой настройки и зависимостью от возможностей выбранной платформы.
Troubleshooting: какие проблемы всплывают чаще всего

Первая и самая частая беда — плохие данные. Если логи нод обрезаются, метрики пропадают, а инциденты размечены от случая к случаю, любая модель будет гадать, а не предсказывать. Вторая проблема — смещение данных: сеть обновилась, алгоритм консенсуса поменялся, нагрузка выросла в разы, а модель всё ещё думает, что живёт в прошлом году. Третья — переобучение: Auto‑ML легко строит слишком сложные модели, идеально подогнанные под историю, но бесполезные на новых данных. При отладке полезно устраивать ретроспективы: смотреть, какие инциденты модель пропустила, а где дала ложные срабатывания, и на этой основе пересматривать фичи, период обновления и логику алертов.
- Проверяйте полноту и стабильность метрик до запуска Auto‑ML.
- Закладывайте регулярный пересмотр моделей после крупных апдейтов сети.
- Ограничивайте сложность моделей и проверяйте их на «недавних» инцидентах.
When Auto‑ML is not enough: комбинированный подход
Иногда одной auto ml predictive maintenance platform действительно мало. При очень специфичной архитектуре, кастомных протоколах или нестандартных паттернах нагрузки лучше всего работает гибрид: жёсткие правила для очевидных аварий (например, потеря консенсуса или критический рост орфанов), плюс Auto‑ML для «серой зоны», где нужно уловить слабые сигналы. Поверх этого слоя можно строить более продвинутые сценарии machine learning for blockchain infrastructure management — например, прогнозировать, на каких валидаторах в PoS‑сети скорее всего случатся слэши, или где появятся проблемы с хранением state. Такой комбинированный подход позволяет выжать максимум из ai powered predictive maintenance software, не теряя контроля и прозрачности, которые ценят операционные команды.