Why on-chain datasets are a mess in the first place
If you’ve ever tried to work with raw blockchain data, you know it looks nothing like the polished dashboards in analytics products. Instead, you get hex blobs, low-level opcodes, half-baked event schemas and a ton of spam transactions. Addresses are just hashes, token symbols are inconsistent across chains, and cross-chain bridges copy the same economic event multiple times. Add in MEV bundles, failed transactions, contract self-destructions, upgrades via proxies — and your “simple” dataset turns into a landmine field. That’s why fully manual pipelines die quickly, and why people are pushing toward autonomous on-chain data analytics tools that can observe the chain, learn patterns, and adapt when protocols change without a human constantly rewriting parsers and labels.
Necessary tools: what you actually need to automate this
At the base layer you need reliable node access (own archive node, managed node provider, or both) plus an indexer that can stream blocks, traces, logs and state diffs into your storage. On top of that you’ll want a flexible storage layer: columnar warehouse (like BigQuery/Snowflake/ClickHouse) for analytics and maybe a graph DB for relations between addresses and contracts. For the “intelligence” layer, you combine embeddings over bytecode and ABI metadata, a rules engine, and ML models that classify transactions and entities. Finally, you wrap this into an on-chain data labeling platform with APIs, schedulers and monitoring so that data cleansing and labeling jobs can run continuously, not as one-off scripts someone forgets about three months later.
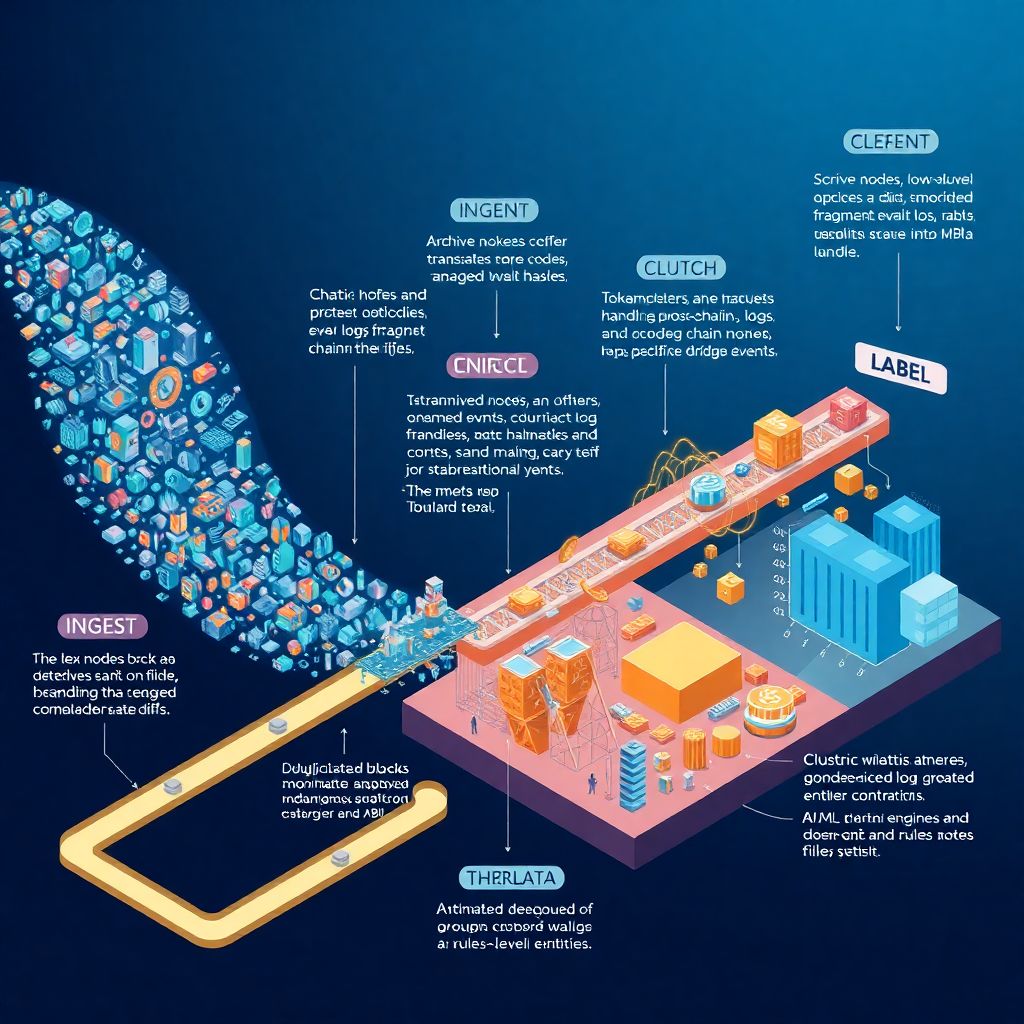
Step-by-step pipeline: from raw chain to usable labels
Think of the pipeline as four big stages: ingest, clean, enrich, label. During ingest, you capture raw blocks, logs, internal traces and contract creations, preferably in near real time. Cleaning is where blockchain data cleansing automation kicks in: you deduplicate mirrored events, normalize chain-specific quirks, decode logs against ABIs, handle reorgs and mark failed transactions. Enrichment is about adding context — token metadata, protocol registries, price feeds, clustering addresses into entities. Labeling then uses that enriched graph to assign semantic tags: “DEX swap,” “bridge deposit,” “lending liquidations,” “CEX hot wallet,” “NFT marketplace bot,” and so on. Crucially, each stage is designed to be re-runnable so model or rules updates can retroactively fix earlier data.
Making the pipeline actually autonomous
Autonomy comes from feedback loops and dynamic configuration instead of frozen ETL code. When a new contract starts generating large volumes of events, the system can flag it, try to infer its interface by matching function selectors, and propose an ABI hypothesis. ML models watch familiar protocols for layout changes and fire alerts when log patterns drift. The rules engine can download new verified ABIs, adjust decoders, and rerun failed jobs. Metrics like “percentage of decoded logs” or “share of unlabeled volume” are tracked over time; when they degrade beyond thresholds, the system automatically schedules reprocessing or triggers retraining. Human input still exists, but it’s more like approving suggestions than writing new parsers every week.
Case 1: Cleaning up DeFi volume for a risk team
A DeFi risk team at a mid-size fund wanted daily exposure reports: how much of their portfolio sat in lending, AMMs, options, perps, and bridges across five EVM chains. Their first approach used a set of hand-written SQL scripts over a public dataset, and numbers jumped by 20–30% whenever protocols upgraded or launched new pools. They moved to a pipeline where new pools and markets were auto-discovered based on factory contracts and bytecode similarity. The system matched unknown events to known DeFi interaction types by comparing argument patterns and value flows. Within a month, they cut manual maintenance from several hours per day to brief weekly reviews, while historical statistics stayed stable across protocol upgrades and new chain launches.
Case 2: NFT wash trading detection at scale
Another real-world case: an NFT marketplace analytics startup needed to identify likely wash trades across Ethereum and a couple of L2s. Raw on-chain data showed endless transfers between fresh wallets, often via obscure marketplaces and custom contracts. They built a semi-autonomous labeling layer that clustered addresses using graph embeddings and tracked trade patterns like rapid back-and-forth sales between small groups, constant stair-step price increases without external bidders, and heavy use of newly funded wallets. Labels like “probable wash trader cluster,” “market-maker bot,” and “organic collector” were assigned automatically and regularly reevaluated as more data arrived. This let them surface cleaner volume metrics that projects used in pitch decks and investor reports instead of inflated raw on-chain counts.
Tooling choices: build vs buy vs “as a service”

Not everyone wants to manage indexers, ML infrastructure and a warehouse. That’s why “web3 data labeling as a service” offerings have appeared: they run the infra, you consume APIs and dumps. If your use case is specialized — say, niche derivatives protocols or long-tail NFT collections — you might still need custom logic on top, but the heavy lifting of ingestion and generic decoding is handled. Larger players often combine both: internal pipelines for mission-critical metrics and external services as backfill or validation. Regardless of choice, it helps to treat labeled data as a product: clear schemas, versioning, changelogs, and documented SLAs for freshness and backfills, so downstream teams aren’t surprised by re-computed histories.
Troubleshooting: usual suspects and how to fight them
Most production issues are surprisingly mundane. Latency spikes usually trace back to indexers falling behind or warehouse limits; the fix is better backpressure and buffering rather than exotic ML tweaks. Label drift — where “DEX trade” starts catching weird edge cases — often comes from silent protocol changes; monitoring precision/recall on a small manually-audited sample catches this early. Chain reorgs cause inconsistent aggregates if you don’t model block finality explicitly. Cross-chain bridges produce double-counted volumes when on-chain legs are labeled as separate economic events; treating bridge contracts as transfer tunnels helps. When debugging, it’s useful to replay a small block range through the entire pipeline and compare intermediate artifacts step by step instead of poking at the final tables only.
Making enrichment robust and auditable
Enrichment is where subtle bugs sneak in. For example, price feeds can be delayed or manipulated, and if you tag a liquidation as “profitable” using wrong prices, all downstream analytics inherit that error. Mature systems maintain provenance: every label and enriched field carries references to the input sources and versions of rules or models used. That also matters when using external blockchain dataset cleaning and enrichment services; you want the ability to reproduce how a particular row in your analytics warehouse was created. Storing intermediate graph representations — address clusters, entity types, contract families — in separate datasets makes it easier to inspect and correct misclassifications without rerunning the entire history from raw chain data.
Closing the loop with human review
Even in an “autonomous” setup, humans remain in the loop, just at a higher level. Analysts periodically sample labeled data, mark obvious mislabels, and feed that back into training sets or rules. Power users get UI panels to propose new protocol templates, override entity types for important addresses, or mark one-off anomalies. One team, for instance, discovered that a big centralized exchange was experimenting with a new smart contract router; their labels initially marked it as a DeFi aggregator, but after a short review they locked it as a CEX router. The system propagated that decision across all subsequent blocks while keeping earlier mislabels for audit, showing how autonomy and curated oversight can comfortably coexist.
Where this all heads next
The line between ETL, analytics and labeling is getting blurrier. Some stacks now expose the entire pipeline — from raw blocks to high-level events — as a programmable on-chain data labeling platform, where you can deploy custom detectors as code that participates in shared infra, much like cloud functions. As chains proliferate and protocols get more composable, systems that rely purely on manual tracking will fall behind. Pipelines that continuously observe, learn, and self-correct will become the norm, while manual work shifts toward defining what “correct” actually means for a use case: risk, compliance, growth, research. In that sense, autonomous pipelines don’t remove humans, they just free them from babysitting scripts and let them focus on the harder, more interesting questions.