Why autonomous risk scoring matters in NFT marketplaces
In 2025 the hype around NFTs has cooled, но the fraud didn’t go anywhere. Wash trading, stolen wallets, fake collections and insider flipping still poison liquidity. Autonomous risk scoring is a way to let the platform itself, not a tired analyst, decide which users and trades look unsafe. Instead of manual reviews it uses rules plus machine learning to assign a numeric risk score to every wallet, collection and transaction in real time, blocking or throttling the worst actors before they touch your order book or payouts queue.
Key terms: putting the jargon in order
Risk score is a dynamic number, often from 0 to 100, reflecting how likely an entity is linked to fraud, sanctions or abuse. An entity can be a wallet, user account, collection, listing or even an IP address. An autonomous engine means that scoring, alerts and many actions are triggered automatically, without waiting for human approval. In this context nft marketplace fraud detection software is a stack of services that ingest blockchain data, marketplace events and external risk feeds, then recompute those scores constantly as new information arrives.
How the scoring engine is wired inside the platform
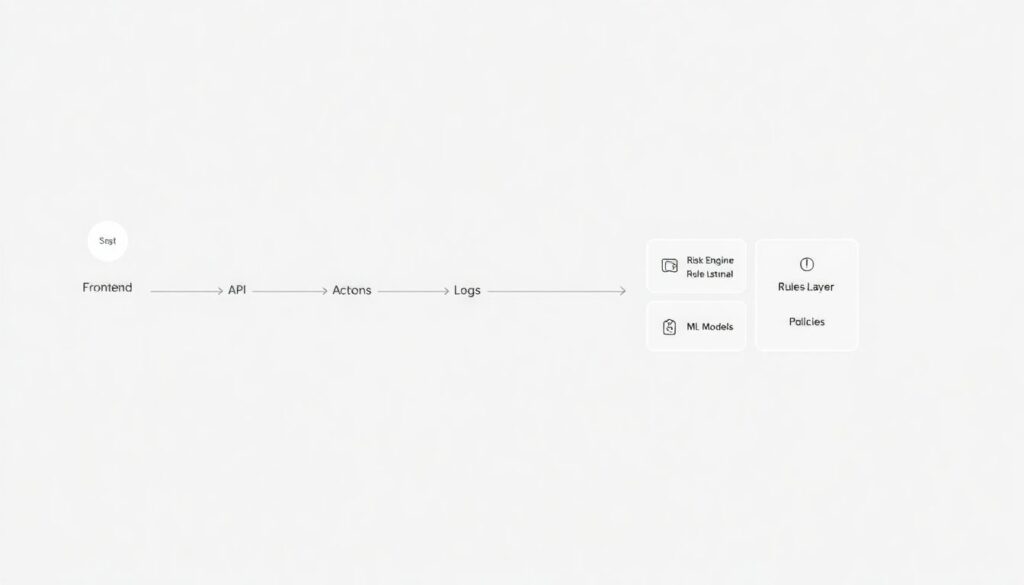
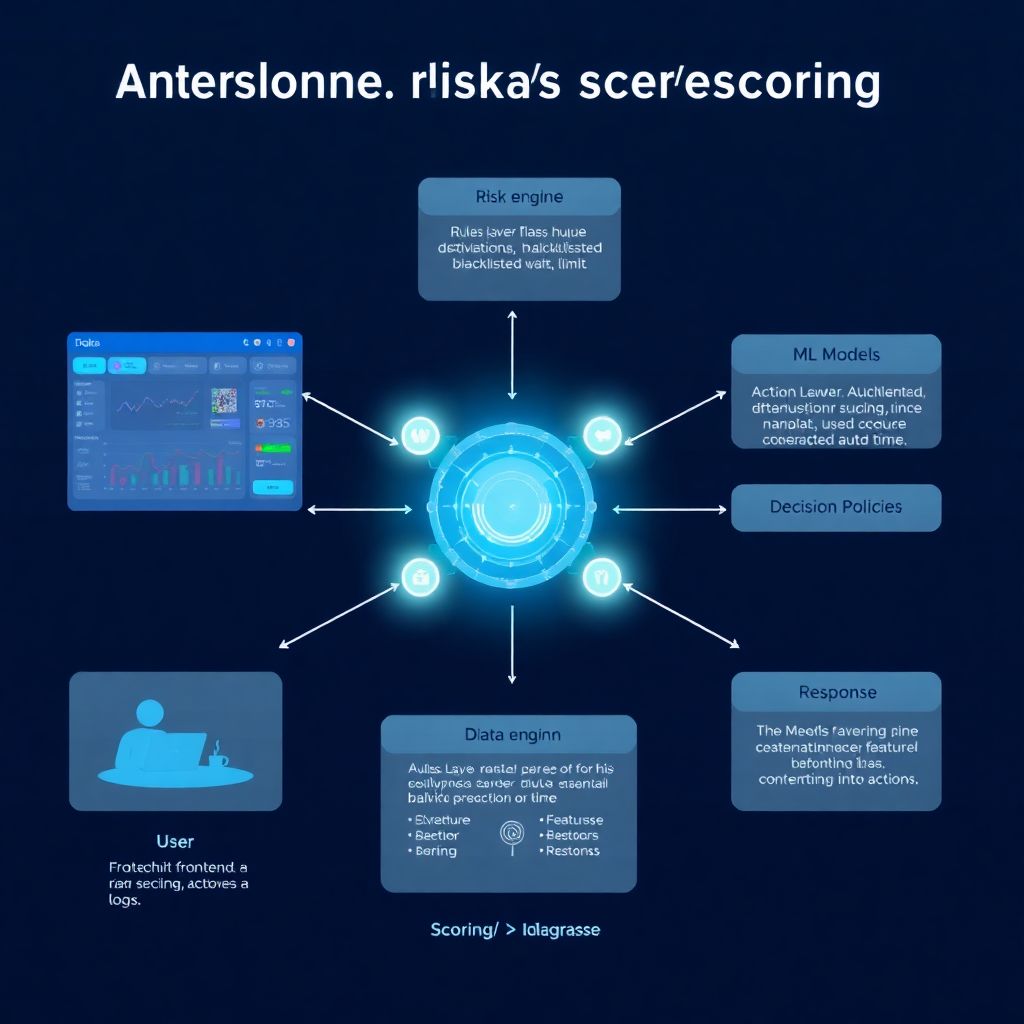
Picture a simple diagram in text: [User → Frontend → API → Risk Engine → Actions → Logs]. The API sends every critical event, like listing, bid or withdrawal, to the engine. The engine has three internal blocks: rules layer, ML models and decision policies. Rules check obvious patterns, like huge price deviations or blacklisted wallets. ML models evaluate subtle behavior sequences across time. Policies translate risk score into actions: pass, review, block or limit. This architecture turns the automated risk scoring solution for nft marketplaces into a reusable microservice instead of a pile of ad‑hoc scripts.
What data feeds the engine: signals that really matter
Effective scoring depends on signals. On-chain data covers transfer history, links to mixers, known hacks and bridges. Marketplace data adds listings, offers, cancellations, device fingerprints and geo. Social and OSINT inputs highlight fake influencers or plagiarized collections. A typical nft marketplace transaction monitoring platform correlates these sources into features like “time between mint and flip”, “share of trades with the same counterparty” or “average price deviation”. The richer the features, the better the difference between a real collector, a professional trader and a wash‑trading farm with hundreds of scripted wallets.
Text diagram: from raw events to a risk score
Imagine another diagram: [Events] → [Feature Extraction] → [Scoring] → [Response]. At the first step raw logs and blockchain transactions are normalized. Feature extraction converts them into numeric vectors, like counts, ratios or flags of suspicious behavior. Scoring combines rules (if price > 5x floor then +15 risk) and ML outputs (model says 0.82 probability of wash trading). The final risk score triggers the response: silently raise fees, freeze withdrawal, ask for KYC or send to analyst queue. This pipeline lets the ai-powered risk management system for nft trading platforms adapt quickly by updating either rules or models.
How it compares to traditional analytics and manual review
Old‑school antifraud relied on batch reports and human intuition. That style works when you have a few dozen tickets per day, but breaks with thousands of micro‑transactions per minute. Autonomous risk scoring is narrower than generic analytics dashboards: it has one job, produce a calibrated risk score per entity. Compared to static blocklists it reacts to context, for instance lowering risk when a user survives time and passes extra checks. Against conventional BI it wins on latency, because its logic is built into the request path, not after‑the‑fact offline queries from the data warehouse.
Implementation steps: from idea to live defense
1. Define goals and scope: decide whether you focus on wash trading, stolen assets, sanctions or all of the above. Describe clear metrics like reduced chargebacks and fewer support tickets.
2. Integrate data: connect node providers, logs, identity vendors and any nft compliance and aml tools for marketplaces you already use. Ensure you can replay historical data to train and test models.
3. Build and tune policies: start conservative with high‑risk blocks and medium‑risk reviews, then gradually add automated actions such as dynamic withdrawal limits and instant delisting for cloned collections.
Compliance, AML and regulator expectations in 2025
By 2025 many jurisdictions treat large NFT venues almost like virtual asset service providers. That means expectations around KYC, sanctions screening and suspicious activity reporting keep rising. Instead of hiring an army of analysts, marketplaces plug their identity vendors and sanction lists into the same scoring engine, turning it into a layer of nft compliance and aml tools for marketplaces. When a regulator asks why a risky user was allowed to trade, the platform can provide a clear timeline: scores, triggered rules and analyst decisions, all backed by immutable logs and reproducible models.
Where this is heading next: forecast for 2025–2030
Over the next five years risk scoring will move from “nice to have” to standard infrastructure, like payment gateways. We’ll see modular scoring APIs that small platforms can drop in without a dedicated data team, the way Stripe democratized payments. On‑chain reputation will likely be portable: high‑risk scores tied to wallets may follow them across ecosystems, while privacy‑preserving proofs hide sensitive details. As generative bots start trading NFTs at scale, expect scoring models to focus more on behavioral biometrics and cross‑platform graph analysis that is harder for scripts to fake convincingly.