Why blockchain sharding needs AI right now
Blockchain sharding sounded like a silver bullet: split the network into shards, process transactions in parallel, and enjoy massive throughput. In practice, it’s messier. Workload is uneven, cross‑shard communication is expensive, validator sets drift in quality, and security assumptions get shaky under real traffic. That’s exactly where AI-powered optimization of blockchain sharding starts to look less like buzzword bingo and more like basic survival for high‑load networks.
At scale, manual tuning just doesn’t work. You can’t have humans constantly deciding how many shards to run, how to allocate validators, or when to rebalance state. The dynamics change block by block. AI fills this gap by learning patterns in network behaviour and applying them in near real time, essentially becoming a control layer over the sharding mechanism.
—
Key terms, explained without fluff
Sharding
Sharding in blockchains is the partitioning of state and transaction processing across multiple subsets of the network (shards), each handling a portion of the workload. Validators are assigned to shards, and each shard can produce blocks somewhat independently, with finality enforced by a beacon or coordination chain.
Short version: one big chain is split into many smaller chains that talk to each other.
AI-powered optimization
AI-powered optimization here means using machine learning and related techniques to automatically adjust sharding parameters and network topology. This includes:
– Predicting load on each shard
– Allocating validators and resources
– Tweaking cross‑shard routing policies
– Detecting anomalies and attack patterns
Unlike static rules, these models are trained on historical and live data and continuously updated.
Layer 1 performance optimization in context
ai driven layer 1 blockchain performance optimization is about improving throughput, latency, and security guarantees at the base protocol level, not by slapping another Layer 2 on top. For sharded systems, that means smarter scheduling, better validator assignment, and adaptive state management directly inside the consensus and networking layers.
—
What AI actually optimizes in sharding
1. Dynamic shard sizing and splitting
One of the central blockchain sharding optimization solutions is dynamic shard sizing. Instead of having a fixed number of shards, an AI model estimates the upcoming workload based on:
– Recent transaction volume
– Fee pressure and mempool composition
– Time‑of‑day / day‑of‑week patterns
– Application‑specific spikes (NFT drops, token launches, etc.)
If the model detects that a subset of smart contracts or addresses is about to hammer a given shard, it can recommend:
– Temporarily increasing capacity for that shard
– Splitting hot contracts into separate sub‑shards or execution pools
– Pre‑warming new shards by moving validators before congestion hits
This turns sharding from a static design decision into a fluid resource allocation problem.
2. Smarter validator and node assignment
The naive approach is to assign validators to shards randomly or with simple heuristics. It works on paper but struggles in adversarial or highly uneven scenarios. An AI‑assisted scheduler can:
– Infer which validators are correlated (e.g., same ASN, geography, or ownership)
– Spread them across shards to maintain fault tolerance
– Match resource‑heavy shards with more powerful nodes
– Minimize gossip delays by considering network latency graphs
This is especially relevant for any enterprise blockchain sharding platform, where you often know more about node operators (hardware profiles, network connectivity, reliability history) than in a fully anonymous public chain.
—
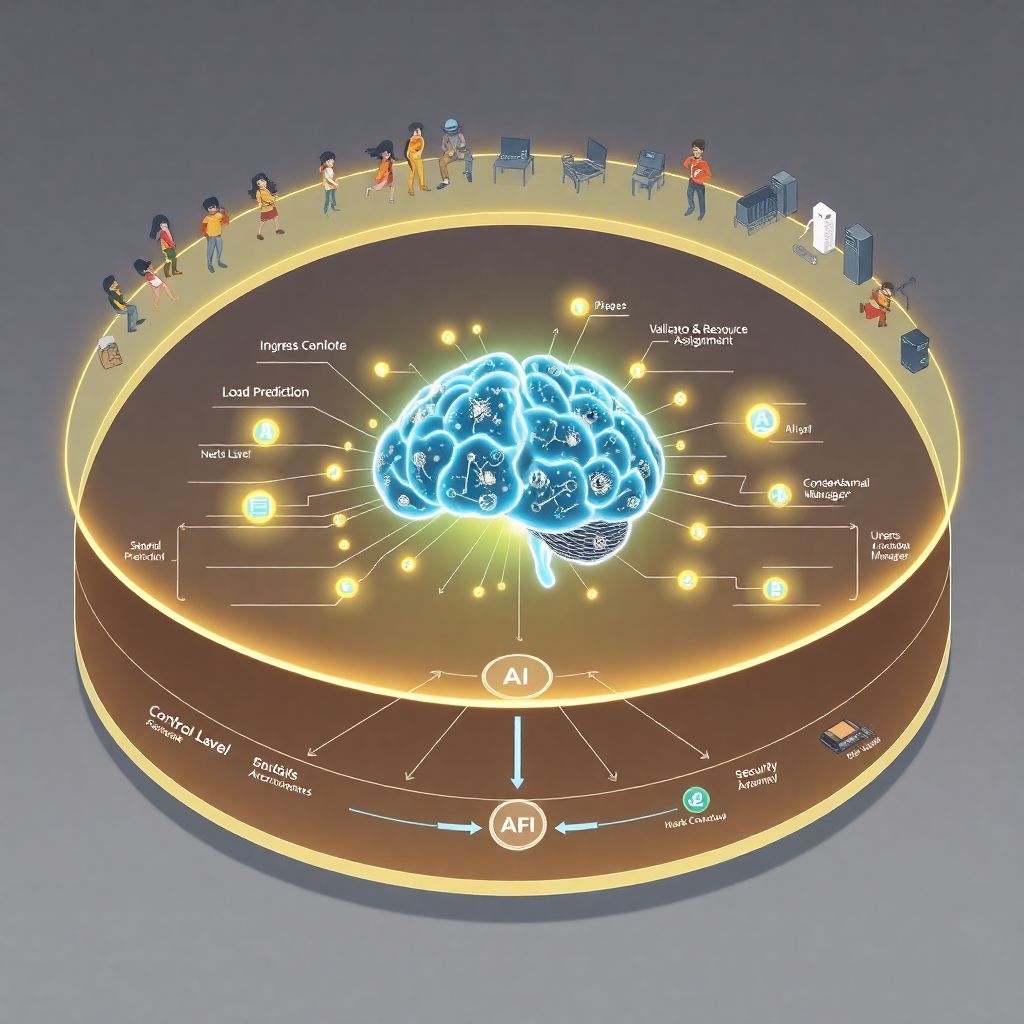
Text diagram: how AI fits into a sharded blockchain
Imagine the following simplified architecture:
– [Clients & dApps]
↓ send transactions
– [Ingress Layer] — collects transactions, labels them by shard / contract / app
↓ feeds metrics
– [AI Controller]
– Module A: Load prediction
– Module B: Validator & resource assignment
– Module C: Security & anomaly detection
↓ produces decisions / parameters
– [Consensus & Shard Manager]
– Adjusts shard count
– Reassigns validators
– Updates routing rules
↓
– [Shards 1..N] — execute transactions & produce blocks
↑ telemetry
– [Monitoring Layer] — performance and security metrics go back into the AI
In text form, think of it as a feedback loop:
Telemetry → AI models → Sharding policies → On-chain behaviour → New telemetry.
—
How this compares to “classic” scalability tricks
Static sharding vs AI‑adaptive sharding
Traditional sharding schemes are essentially static: the protocol fixes the number of shards, updates assignments every epoch, and uses simple randomization to keep things secure. This works decently while demand is predictable and evenly distributed. The moment you have sudden micro‑bursts on a few DeFi contracts or a popular game, the system can’t react fast enough.
AI‑adaptive sharding brings:
– Proactive scaling – capacity is spun up before congestion, not after the network is already clogged.
– Topology awareness – the system learns which shards tend to interact and co‑locates related state to reduce cross‑shard messages.
– Continuous tuning – parameters change block by block, not only at epoch boundaries.
AI vs hand‑crafted heuristics
You could in theory hand‑craft clever rules: “If shard X is above 80% utilization for 10 minutes, split it.” But real networks aren’t that simple. Holes in heuristics show up under attack, during coordinated liquidations, or in mixed DeFi + NFT workloads.
ai powered blockchain scalability tools go beyond “if‑else trees” by:
– Learning non‑obvious patterns (e.g., mempool composition as an early signal of a future spike)
– Aggregating multiple signals (network latency, gas prices, contract call graphs)
– Self‑calibrating based on outcomes (was the split beneficial? did it reduce orphaned blocks?)
In short, heuristics work until they don’t; models degrade gracefully and can be retrained.
—
Under the hood: models and data
Data sources for AI‑driven sharding
To optimize sharding, the AI system typically ingests:
– Block and transaction streams (volumes, gas usage, fees)
– Mempool data (pending tx types, contract addresses, signatures of known bots)
– Network metrics (latency between nodes, bandwidth, failure rates)
– Validator stats (uptime, slashing incidents, performance)
– Application‑level signals (scheduled auctions, protocol governance events)
All of this forms a dense time series and graph structure that’s perfect for modern ML.
Relevant model types
1. Time‑series forecasting models (e.g., gradient boosting, transformers)
– Predict short‑term congestion on specific shards or contracts.
2. Graph neural networks (GNNs)
– Model relationships between addresses, contracts, shards, and validators.
– Help answer: “Which contracts should live together?” and “Which validators must be separated?”
3. Reinforcement learning (RL) agents
– Explore policies for splitting, merging, and reallocating shards.
– Reward function mixes throughput, latency, and security metrics.
4. Anomaly detectors (autoencoders, isolation forests)
– Spot unusual patterns that could imply an attack or a systemic bug.
Together, these form the backbone of advanced blockchain infrastructure optimization with artificial intelligence instead of leaving operations to static configuration files.
—
Expert recommendations for designing AI‑driven sharding
From theory to production: what seasoned engineers insist on
Blockchain architects who’ve actually tried to ship these systems repeat the same warnings and recommendations. Here are the core points, generalized from multiple expert interviews and design docs.
1. Make AI advisory, not absolute (at first)

Experienced protocol designers recommend starting with AI as a “co‑pilot,” not an all‑powerful controller. That means:
1. The AI proposes shard splits/merges and validator reassignments.
2. A deterministic policy layer checks proposals against strict safety constraints.
3. Only then does the protocol enact changes, preferably at well‑defined boundaries (e.g., epoch transitions).
This hybrid model keeps experimentation safe while still reaping benefits.
2. Encode invariants in code, not in the model
Security engineers are adamant: never rely on a neural network to “remember” basic safety rules. Things like:
– Max attacker stake per shard
– Minimal number of independent operators per shard
– Boundaries on how fast you can move validators around
should live in protocol logic as hard constraints. The model is allowed to optimize *within* that region, not redefine it.
3. Keep the model simple enough to reason about
There’s a strong expert bias against excessively complex ensembles hidden behind black‑box APIs. Operationally, you want:
– Models small enough to be evaluated within tight block time limits
– Clear input features that can be independently verified
– Versioned, reproducible training pipelines
The recommendation is often: “Use the smallest model that gives you a meaningful gain; don’t chase leaderboard scores.”
4. Design for model failure modes
AI‑assisted protocols must assume the model will sometimes be wrong, outdated, or even adversarially manipulated. Senior reliability engineers suggest:
– A conservative fallback mode with static sharding parameters
– Rate limits on how aggressively the AI can change the topology
– Continuous monitoring for “thrashing” behaviour (constant shard splits/merges)
In other words, the smart move is not to trust the model’s brilliance but to manage its mistakes.
—
Realistic use cases and scenarios
Scenario 1: Predictive congestion avoidance
A gaming dApp announces a big in‑game event. Historically, similar events led to multihour congestion in the affected shard. An AI controller sees the pattern emerging in the mempool—many small transfers and NFT‑related calls targeting a cluster of contracts.
The system:
– Proactively increases the shard’s capacity or duplicates state across a temporary “event shard”
– Assigns more performant validators to handle the event
– Adjusts fee policies slightly to prioritize core gameplay over low‑value spam
Users experience minor fee increases but no catastrophic slowdown. The same mechanism would be extremely hard to tune manually.
Scenario 2: Mitigating cross‑shard bottlenecks
DeFi protocols often build on top of each other: DEX → lending → derivatives. When these sit on different shards, cross‑shard calls can become a bottleneck. By analysing call graphs, a GNN notices that certain shards have extremely dense interactions.
Over time, the AI recommends:
– Repacking hot DeFi contracts into fewer, interconnected shards
– Co‑locating oracle updates with the consuming protocols
– Re‑routing some traffic through optimized hubs
This turns a spaghetti of cross‑shard messages into more structured flows and measurable latency improvements.
—
Integration in enterprise and public environments
Enterprise flavor: more control, more data

In enterprise settings, ai powered blockchain scalability tools can leverage richer meta‑data:
– Known node operators and their SLAs
– Predictable business cycles (end‑of‑month batch runs, regulatory reporting)
– Explicit throughput targets and latency budgets
An enterprise blockchain sharding platform can thus run heavier models off‑chain, feed condensed decisions on‑chain, and even allow governance committees to approve or veto certain optimization strategies. The regulatory and compliance angle also means auditability is crucial: logs of AI decisions need to be preserved and explainable.
Public networks: censorship‑resistant but data‑scarce
Public chains have less control and less trusted meta‑data. Models must:
– Work with noisy, sometimes adversarial inputs
– Avoid favouring specific addresses or regions
– Be designed in a way that’s transparent enough for the community to accept
Here, the emphasis is on open‑sourcing the AI policy logic and making sure the community can reproduce model training, or at least verify the behaviour via simulations.
—
Challenges and open questions
Who trains and updates the models?
One tough governance question: who decides how the AI behaves? Options include:
– Core dev teams maintaining “official” models
– Independent optimization providers competing to supply better models
– On‑chain governance choosing between versioned policies
Each comes with risks—centralization, capture, or endless coordination overhead.
Attack surfaces unique to AI‑assisted sharding
New power always comes with new ways to break things. Attackers might:
– Poison training data to push the system into insecure shard configurations
– Flood the network with deceptive traffic patterns to trigger wasteful scaling decisions
– Exploit predictability in the controller to front‑run topology changes
Designers must assume that anything that can be gamed *will* be gamed, and build robust detection and throttling mechanisms into the controller.
—
Where this is heading
The direction of travel is clear: we’re moving from hand‑tuned protocols to self‑optimizing ones. AI‑powered optimization of blockchain sharding is less about replacing engineers and more about giving the protocol a nervous system that reacts in real time.
As blockchains become the substrate for high‑frequency, global‑scale applications, static designs will hit their limits. Intelligent blockchain sharding optimization solutions, embedded as part of ai driven layer 1 blockchain performance optimization stacks, will quietly handle the messy orchestration under the hood.
The practical path forward is incremental: start with advisory models, enforce strict invariants at the protocol layer, observe real‑world behaviour, and only then let the AI take on more control. Done thoughtfully, this doesn’t just make sharded networks faster—it makes them more resilient, more predictable, and ultimately more usable for everyone building on top of them.