
What are blockchain-powered autonomous data marketplaces, really?

Imagine a data marketplace that doesn’t sleep, doesn’t wait for managers to approve deals, and doesn’t rely on a central company to “be honest.” Data sets get listed, priced, verified, traded, paid for, and even revoked automatically — with rules encoded in smart contracts.
That’s the core idea behind a blockchain-powered autonomous data trading platform blockchain: data as a digital asset, governed by code, not by manual processes.
—
A short historical detour: how we got here
From web portals to protocol-driven markets
If you rewind to the early 2010s, “data marketplaces” mostly meant centralized web portals: one company aggregating data from providers and reselling it to buyers. Think of:
– Marketing and ad-tech data brokers
– Financial data providers
– Location and mobility data vendors
They were useful, but they had three chronic problems: opaque pricing, questionable consent, and almost no technical guarantees about how data would be used once purchased.
Then came the 2017–2018 wave of blockchain hype. Projects promised a decentralized data marketplace solution for everything: IoT data, personal data, health records, AI model feeds. Many launched tokens before they had working products. Unsurprisingly, most collapsed with the crypto winter.
Yet a few key ideas survived and matured between 2019 and 2024:
– Smart contracts can represent data access rights, not just payments.
– On-chain incentives can reward honest behavior (provide good data) and punish malicious actors (fake or low-quality data).
– Zero-knowledge proofs and secure enclaves can let you compute on data without fully revealing it.
By 2023–2024, we started seeing more serious experiments: consortium-led enterprise blockchain data exchange networks in finance, energy, and supply chains; and early tokenized data marketplace SaaS offerings targeting AI teams starved for domain-specific datasets.
Now, in 2025, the buzzwords have quieted a bit, but the infrastructure is finally catching up to the original vision.
—
Basic principles: what makes these marketplaces “autonomous”
1. Data as a first-class on-chain asset
The marketplace doesn’t store your raw data on-chain (that would be expensive and risky), but it does store:
– References (hashes, URIs, content identifiers)
– Metadata (schema, source, timestamp, licensing terms)
– Ownership and access policies
On-chain records make data assets addressable and tradable like tokens. This is what many people implicitly mean when they say *blockchain data marketplace platform*: a layer where datasets behave like programmable assets.
Short version: the chain tracks who can do what with which dataset, under which conditions.
—
2. Smart contracts as market logic
In an autonomous marketplace, a big chunk of what used to be “operations” is just smart contract code:
– Listing and delisting datasets
– Price discovery and dynamic pricing
– Payment splitting between multiple contributors
– Access control: granting and revoking permissions
– Dispute resolution and slashing of bad actors
Instead of an operations team reviewing every data licensing deal, you get pre-defined, auditable logic. If the rules say “pay-per-query” or “subscription for 30 days,” that’s exactly what happens, automatically.
This is where we move beyond just *blockchain plus payments* toward a genuinely autonomous blockchain data marketplace platform.
—
3. Trust minimization, not “perfect trust”
The goal isn’t to magically make everyone honest. The goal is to make cheating:
– Detectable
– Economically irrational
– Reputationally expensive
This usually involves a combination of:
– Cryptographic proofs (integrity of data, consistency over time)
– Economic stakes (collateral that can be slashed)
– Reputation systems (on-chain ratings, proofs of past behavior)
Instead of trusting an intermediary, participants rely on protocol rules. The phrase *decentralized data marketplace solution* is accurate only when honest behavior doesn’t depend on a single trusted company.
—
4. Separation of data, control, and compute
Modern architectures tend to split things into three layers:
– Data storage: IPFS, Filecoin, cloud storage, on-prem data lakes
– Control and incentives: blockchain, smart contracts, tokenomics
– Compute: secure enclaves, MPC, ZK-proofs, off-chain analytics
The chain orchestrates who can run what computation on which data and under what terms, but heavy lifting happens off-chain. This keeps the system efficient and privacy-preserving.
—
Real-world flavors and examples
Instead of listing project names that age quickly, it’s more useful to look at patterns that have emerged by 2025.
1. Industry consortia: enterprise blockchain data exchange
Enterprises have learned (sometimes painfully) that sending CSVs over email and FTP is not a sustainable model for regulated industries. So we’ve seen:
– Banks and insurers pooling risk, fraud, and KYC signals under shared rules
– Logistics companies sharing shipment, customs, and IoT sensor data
– Energy firms exchanging grid, consumption, and forecasting data
Here, an enterprise blockchain data exchange often runs as a permissioned network:
– Participants are known entities (banks, utilities, logistics providers)
– Governance is shared via legal agreements *and* smart contracts
– Data access is tightly audited for compliance (GDPR, HIPAA, etc.)
Autonomy shows up in automated settlement and access control: once policies are encoded, day-to-day data sharing doesn’t require manual approval chains.
—
2. AI-focused tokenized data marketplaces
The explosion of generative AI pushed demand for niche, high-quality datasets through the roof. That’s where tokenized data marketplace SaaS offerings came in:
– Domain experts (e.g., radiology groups, legal publishers, industrial IoT operators) contribute specialized data
– The platform tokenizes access rights and revenue shares
– AI companies (or internal AI teams) subscribe to, fine-tune on, or query those datasets via APIs
Key patterns you see here:
– Revenue automatically routed to data contributors via smart contracts
– Usage-based pricing: pay-per-query or per training run
– Fine-grained licensing: “you can train your model, but not resell the raw data” encoded as enforceable logic
This is one of the clearest use cases for a blockchain data marketplace platform that feels “autonomous” from the perspective of contributors: once they onboard, they mostly just watch usage and revenue, instead of manually negotiating every deal.
—
3. IoT and real-time telemetry
There’s also a class of autonomous data trading platform blockchain deployments focused on real-time data:
– Smart city sensors (traffic, pollution, noise)
– Vehicle telemetry (fleet management, insurance)
– Industrial IoT (machines, pipelines, turbines)
Core elements here:
– Devices or gateways publish signed data feeds
– Buyers subscribe to specific feeds or filtered streams
– Smart contracts handle micro-payments or periodic settlements
The autonomy aspect is pronounced: devices effectively become economic agents, selling their streams under configurable rules.
—
How these marketplaces typically work: a quick walkthrough
To make it concrete, let’s walk through the lifecycle of a dataset in such a marketplace.
1. Onboarding the data
A provider (company, research group, or even individual) does the following:
– Uploads data off-chain (cloud, IPFS, on-prem)
– Registers dataset metadata on-chain (schema, description, compliance notes)
– Defines commercial terms and technical policies
These policies might specify:
– Pricing model (fixed, dynamic, auction-based)
– Access level (download vs. “query-only” via secure compute)
– Geographic or sector restrictions (e.g., no use in ad-targeting)
This registration step is where the dataset becomes a programmable asset.
—
2. Discovery and evaluation
Buyers browse or query the catalog:
– Search by domain, schema, quality metrics
– Inspect sample statistics or synthetic previews
– Check provider reputation and provenance trails
Since you usually can’t just hand over full raw data for evaluation, marketplaces rely on:
– Samples with masking
– Differentially private statistics
– Hash-based integrity and versioning
The goal is to give enough signal to decide whether the data is fit for purpose, without breaking privacy or IP.
—
3. Access and usage
Once a buyer chooses a dataset:
– A purchase or subscription contract is executed on-chain
– Access credentials, capabilities, or compute rights are granted
– Payments are locked or streamed (depending on the model)
Usage can look like:
– Direct download for internal analytics
– API-based queries with metering
– On-demand computations in a secure enclave or data clean room
Smart contracts log the usage events that matter for auditing and billing.
—
4. Settlement and incentives
Finally:
– Revenue gets automatically split between stakeholders
– Collateral is adjusted based on behavior (more trust, less required stake)
– Disputes, if any, get resolved via pre-defined workflows
Some systems add extra incentives:
– Rewards for consistent data freshness
– Bonuses for high-quality annotations
– Penalties for provably corrupted or mislabeled data
At scale, this turns into an incentive engine rather than just a storefront.
—
Common misconceptions (and why they matter)
Misconception 1: “Everything goes on-chain”
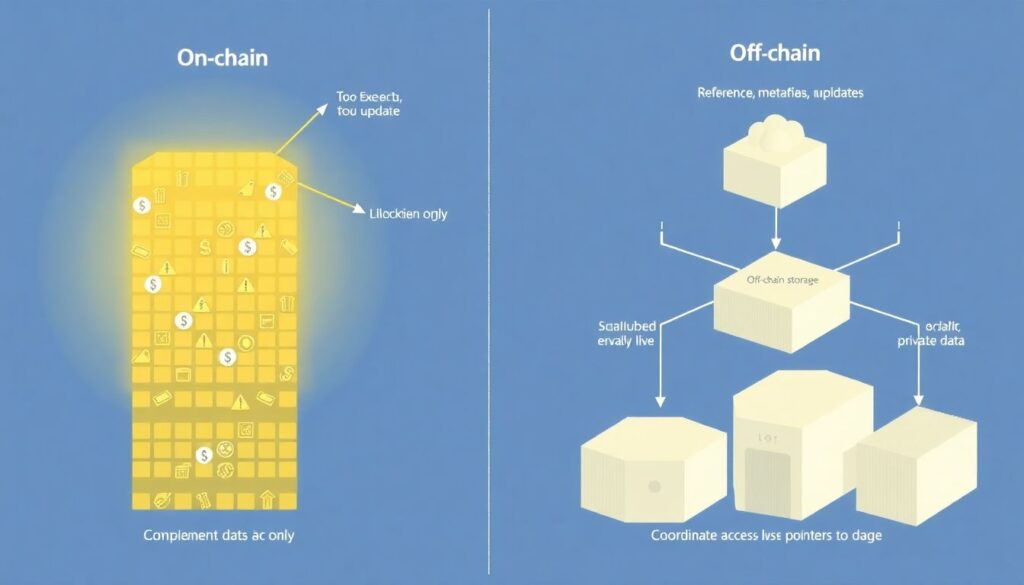
No, and it shouldn’t. Storing full datasets on-chain is:
– Too expensive
– Hard to update
– A compliance nightmare
In serious systems:
– Only references, metadata, and access policies live on-chain
– The actual data lives in storage systems designed for scale and privacy
– The chain coordinates access and economics, not raw bytes
If someone is promising a *decentralized data marketplace solution* that “puts all your data on a public blockchain,” that’s a red flag, not a feature.
—
Misconception 2: “Blockchain magically solves data quality”
Bad data on a decentralized ledger is still bad data — just more persistent. Blockchains help with:
– Tracking provenance and versioning
– Making tampering obvious
– Incentivizing or penalizing contributors
But they don’t automatically:
– Fill missing values
– Fix biases in training data
– Validate domain-specific correctness
Any enterprise blockchain data exchange worth its salt still has robust data governance, validation pipelines, and human oversight on top of the on-chain layer.
—
Misconception 3: “Autonomous means unregulated or unstoppable”
“Autonomous” here refers to:
– Automated execution of rules
– Reduced reliance on manual approvals
– Codified governance
It does *not* mean:
– Immune to regulation
– Non-compliant by design
– Beyond legal reach
In reality, modern designs:
– Encode regulatory constraints into smart contracts
– Log access in ways that make audits easier, not harder
– Support kill-switches and emergency governance actions for critical failures
For regulated data (healthcare, finance, telecom), the only way these systems get adopted is by being more compliant and more auditable than legacy spreadsheets and ad-hoc APIs.
—
Misconception 4: “Tokenization is always speculative”
Tokens in a tokenized data marketplace SaaS don’t have to be speculative casino chips. When done responsibly, they represent:
– Access rights
– Revenue shares
– Governance influence
The key is to tie token economics tightly to real usage:
– No inflation disconnected from actual demand
– No promises of “number go up” unrelated to data utility
– Transparent links between token flows and marketplace activity
If tokens don’t map to concrete rights or services, you’re looking at a finance product, not a data infrastructure product.
—
Where this is heading by 2030 (and what to watch now)
By 2025, a few trends are becoming clear:
– Verticalization: Generic “data marketplaces for everything” are losing to specialized platforms: clinical data, energy grids, mobility, industrial IoT, high-value B2B intelligence.
– Compute-to-data models: More marketplaces are moving away from raw data downloads toward “bring your model to the data,” which reduces leakage risk.
– Interoperability pressure: Large enterprises don’t want ten incompatible networks. Standards for schemas, identity, and attestations are slowly emerging.
If you’re evaluating or building a blockchain-powered autonomous data marketplace today, it’s worth asking:
– How does it help coordinate incentives among multiple parties *better* than existing tools?
– Does it work as a blockchain data marketplace platform (programmable, composable), or just a rebranded data broker?
– Is the autonomous data trading platform blockchain logic actually reducing operational friction, or just adding crypto complexity?
The underlying idea is powerful: turn data exchanges into transparent, programmable, and largely self-operating systems. But realizing that promise requires more than deploying a chain and minting a token. It requires aligning cryptography, economics, regulation, and old-fashioned data engineering into one coherent, evolving protocol — and that’s the real work happening now.