Почему вообще стоит заморачиваться с автономной проверкой целостности данных
Autonomous data integrity verification on blockchains звучит как что‑то академическое, но в реальности это про очень приземлённую вещь: вы хотите быть уверены, что данные, на которых работают ваши смарт‑контракты и приложения, не были тихо подправлены, обрезаны или подменены. Ручные проверки журналов, логов и выгрузок работают до тех пор, пока объём небольшой и команда сидит в одной комнате. Как только появляется несколько цепочек, внешние источники, сложные бизнес‑правила и автоматические выплаты, без автоматизированных гарантий всё начинает разваливаться. Поэтому цель не просто «хранить на блокчейне», а построить цепочку: от появления данных, через их запись, до постоянной верификации без участия человека, чтобы любые аномалии обнаруживались автоматически и как можно раньше, а не после аудита или скандала с утечкой.
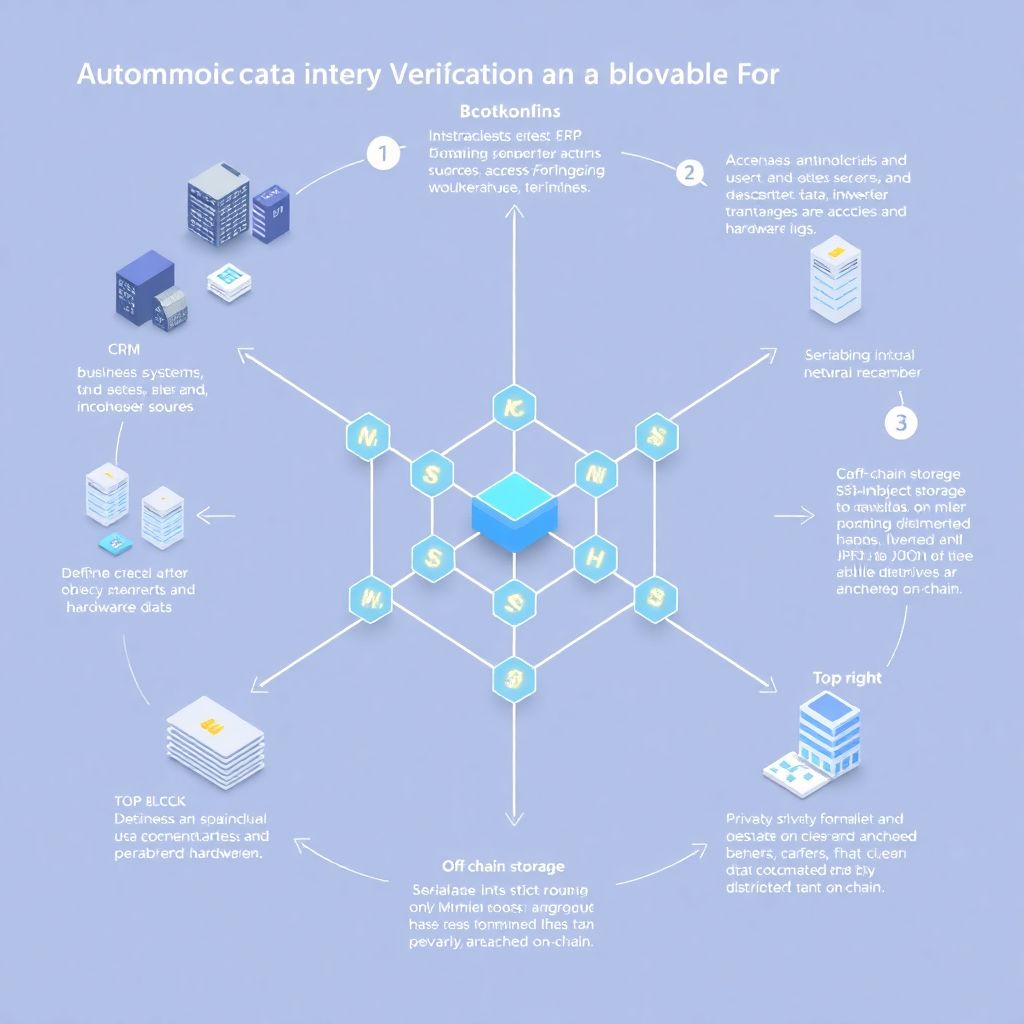
Базовая схема: как вообще выглядит автономная проверка на практике
Чтобы не утонуть в теории, давайте разложим процесс на понятные шаги. Сначала вы чётко определяете, какие данные для вас критичны: это могут быть транзакции пользователей, записи об отгрузках, результаты вычислений, логика доступа к ресурсам. Затем эти данные приводятся к детерминированному формату (например, сериализуются в JSON с жёстким порядком полей), после чего над ними считается криптографический хеш, который попадает в смарт‑контракт. Фактические данные могут жить в базе, объектном хранилище или в IPFS, а цепочка хранит лишь «отпечаток». Дальше включается автоматика: отдельные сервисы или сами контракты регулярно сверяют новые и существующие хеши, отслеживают расхождения и сигналят наружу. Так строятся базовые blockchain data integrity solutions, на которые потом наслаиваются бизнес‑правила и аналитика.
Шаг 1. Определяем границы данных и угрозы, а не сразу пишем контракт
Новички часто начинают с написания контракта, не понимая, что именно и от кого они защищают. Лучше сделать наоборот: сначала описать, какие изменения в данных для вас критичны, а какие допустимы и ожидаемы. Например, адрес доставки может обновиться по согласованной процедуре, а сумма в уже проведённом инвойсе — нет. Затем нужно честно посмотреть на угрозы: злонамеренный администратор базы, уязвимость в приложении, непреднамеренная ошибка миграции или повреждение из‑за сбоя оборудования. Для каждой угрозы вы формулируете требуемые гарантии: что именно вы хотите уметь доказывать через блокчейн через месяц или через год после события. Эта проработка экономит массу времени, потому что избавляет от лишней записи второстепенных данных в цепочку и позволяет сфокусироваться на тех элементах, от которых реально зависит репутация и деньги.
Шаг 2. Выбор типа хранилища и построение «доказуемого» контура
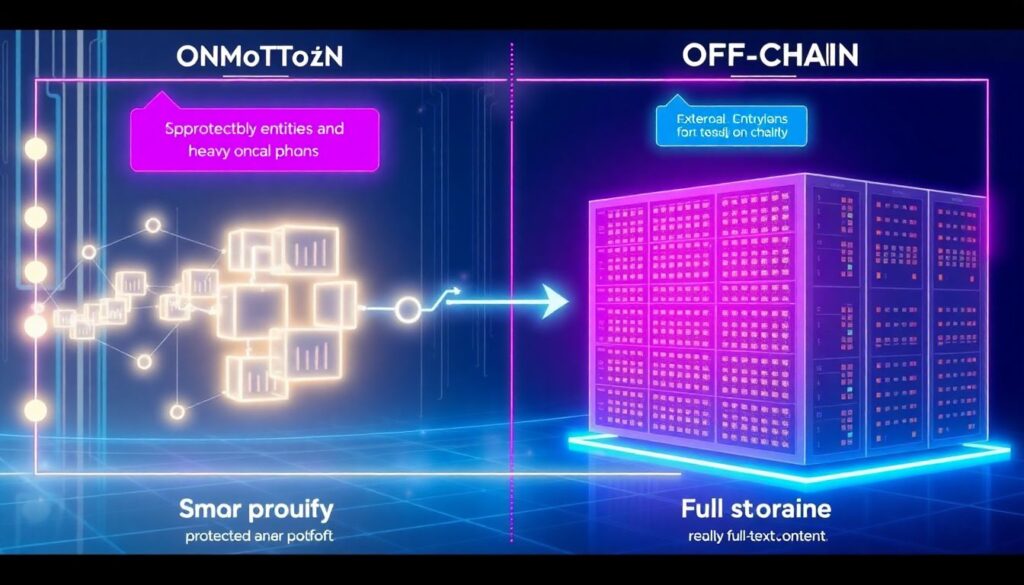
Когда вы понимаете, какие сущности нужно защищать, пора решать, где будут жить сами данные и как вы будете формировать их доказательства. Почти никогда не стоит пытаться хранить всё «как есть» в ончейне: это дорого и медленно. Реалистичный вариант — оставить полнотекстовое содержимое во внешнем хранилище (SQL, NoSQL, S3‑подобные сервисы, распределённые сети) и только периодически фиксировать на блокчейне корневые хеши, мерклизованные деревья или агрегированные подписи. Такой подход позволяет сохранять приватность и масштабируемость, но при этом даёт возможность в любой момент доказать, что конкретная запись действительно существовала в момент её фиксации. Для корпоративных сценариев enterprise blockchain security and data verification строится именно так: линия от бизнес‑системы до чека в блокчейне документируется и автоматизируется, чтобы любой аудит мог её пройти шаг за шагом.
Шаг 3. Смарт‑контракты как автономные «арбитры» целостности
Теперь переходим к смарт‑контрактам, которые и делают верификацию автономной. Контракты не должны просто складывать хеши в массив, иначе вы получите красивый, но бесполезный журнал. Гораздо лучше, когда контракт вшивает в себя правила: какие типы записей допустимы, кто имеет право их публиковать, какие временные ограничения и зависимости действуют между событиями. Тогда любая попытка пропихнуть нелегитимное изменение просто не пройдёт верификацию на уровне самой цепочки. Важно учесть, что контракт — это по сути неизменяемый код, и ошибки в нём станут вашей новой уязвимостью. Поэтому подключайте автономous smart contract auditing services до деплоя и после, чтобы анализировать байткод, права доступа, возможные переполнения и логические дыры, иначе вы легко замените одну проблему другой, просто с более дорогими последствиями.
Шаг 4. Внедрение независимого слоя для постоянного мониторинга

Даже идеально написанный контракт не решит задачу, если никто не следит за тем, как он используется и что происходит на уровне реальных данных за пределами цепочки. Поэтому следующим элементом становится внешний мониторинговый слой. Это сервисы, которые периодически забирают данные из базы или хранилища, повторно считают хеши и сверяют их с тем, что зафиксировано в блокчейне. При любом расхождении они не только поднимают тревогу, но и автоматически фиксируют инцидент в отдельном журнале, чтобы никто не смог «забыть» о проблеме. Такие on-chain data integrity monitoring tools имеют смысл запускать с самого начала, даже в тестовой среде: так вы поймёте, где у вас ломается детерминизм сериализации, какие поля меняются «по умолчанию» и какие сервисы вообще не логируют свои действия, хотя влияют на критичные записи.
Шаг 5. Интеграция с существующими системами и рабочими процессами
Там, где уже есть CRM, ERP, аналитика и отчётность, простой «прикрутим блокчейн» не работает. Автономная проверка целостности должна вписаться в ваши процессы так, чтобы пользователи не чувствовали постоянной боли, а инфраструктура не становилась хрупкой. На практике это значит: ставить адаптеры рядом с существующими сервисами, которые перехватывают или дублируют события, подготавливают их к фиксации и отправляют хеши в блокчейн‑контракты. При этом важно не создавать диких зависимостей: если блокчейн недоступен, операционная система не должна полностью замирать. Вместо этого выстраиваются очереди и ретраи, а пользователи получают понятные статусы: «зафиксировано локально, ожидает подтверждения сети». Так шаг за шагом обычная архитектура превращается в blockchain-based data verification platform, а не в набор хаотических экспериментов.
Типичные ошибки и как новичкам их избежать на старте
Практика показывает, что самые дорогие ошибки происходят не из‑за криптографии, а из‑за архитектурной спешки. Люди либо заливают в цепочку весь объём данных, взрывая бюджеты на газ, либо, наоборот, оставляют на блокчейне слишком мало, лишаясь доказуемости при споре. Ещё одна распространённая проблема — слабая модель идентичности: когда неочевидно, кто именно публикует доказательства и как подтверждается его полномочие. Новичкам стоит начинать с небольшого, замкнутого сценария: взять один критичный бизнес‑процесс, промоделировать угрозы, построить от начала до конца путь данных и только затем писать контракт и вспомогательные сервисы. Не стесняйтесь использовать готовые blockchain data integrity solutions как ориентир, но не копируйте их слепо: каждая отрасль и компания имеет свои ограничения по приватности, скорости и стоимости, и именно они должны диктовать дизайн технического решения.