
Why AI on blockchains desperately needs common data standards
AI on blockchains звучит как идеальный техно-коктейль: прозрачность, доверие, автоматизация, умные инсайты. На практике же всё быстро упирается в грязную, скучную, но жизненно важную вещь — данные и их формат.
Если у тебя нет внятных, согласованных, interoperable data standards for AI on blockchains, любая красивая архитектура превращается в зоопарк костылей, одних только «адаптеров» становится больше, чем полезного кода.
Давай разберёмся по‑человечески:
что такое совместимые стандарты данных, где они реально нужны, какие частые ошибки делают новички и как этого избежать.
—
Что вообще значит «interoperable data standards» в контексте блокчейна и AI
Если по‑простому, это набор договорённостей:
– как хранить данные
– как их описывать (метаданные, схемы, типы)
– как к ним обращаться и проверять их целостность
– как шарить данные между разными цепочками и AI‑сервисами
Когда говорят про enterprise blockchain data standards for AI integration, речь не о красивом PDF‑документе со словами «Standard v1.0», а о реальных:
– схемах (JSON Schema, Protobuf, Avro и т.п.)
– on-chain структурах (стандартизированные форматы событий, логов, хранилищ)
– off-chain протоколах доступа (API, data feeds, подписки, ACL)
– правилах идентификации и версионирования данных
Без этого каждый сервис живёт в своей реальности и AI‑модели получают кашу, а не полезный датасет.
—
Почему это критично именно для AI на блокчейнах
AI не терпит грязных, неоднородных данных. А блокчейн не любит задние дверцы и хаос в структуре хранения.
Когда ты строишь blockchain-based data infrastructure for AI applications, у тебя сразу несколько конфликтующих требований:
– Данные должны быть проверяемыми и неизменяемыми
– При этом они должны быть достаточно гибкими для разных моделей и кейсов
– AI должен свободно забирать информацию из разных сетей и источников
– Комплаенс и приватность нельзя выбрасывать, особенно в финтехе и медицине
Интероперабельные стандарты — это способ договориться, как всё это сочетать, чтобы не ломать каждую новую интеграцию с нуля.
—
Типичные ошибки новичков при работе с AI и блокчейнами
Ошибка №1: «Сначала нафигачим фич, стандарты потом»
Самая частая беда: сначала быстро строят прототип, вообще не думая, какие нужны AI data interoperability solutions for blockchain networks.
В итоге:
– разные сервисы логируют события в разных форматах
– одни поля называются `user_id`, другие `uid`, третьи `customer`
– timestamps в трёх форматах, часть без timezone
– половина полезных метаданных лежит в комментариях к коду или в голове разработчика
AI‑модель потом «съедает» это с боем: требуется куча маппинга, нормализации, ручных правил. Любое добавление нового источника данных ломает старую логику.
Как сделать лучше:
– ввести единый словарь сущностей и полей ещё ДО написания первой версии смарт‑контрактов
– выбрать один формат для временных меток и идентификаторов
– сразу описывать структуру данных схемами (например, JSON Schema) и версионировать их
—
Ошибка №2: «Одна цепочка — один стандарт, остальное неважно»
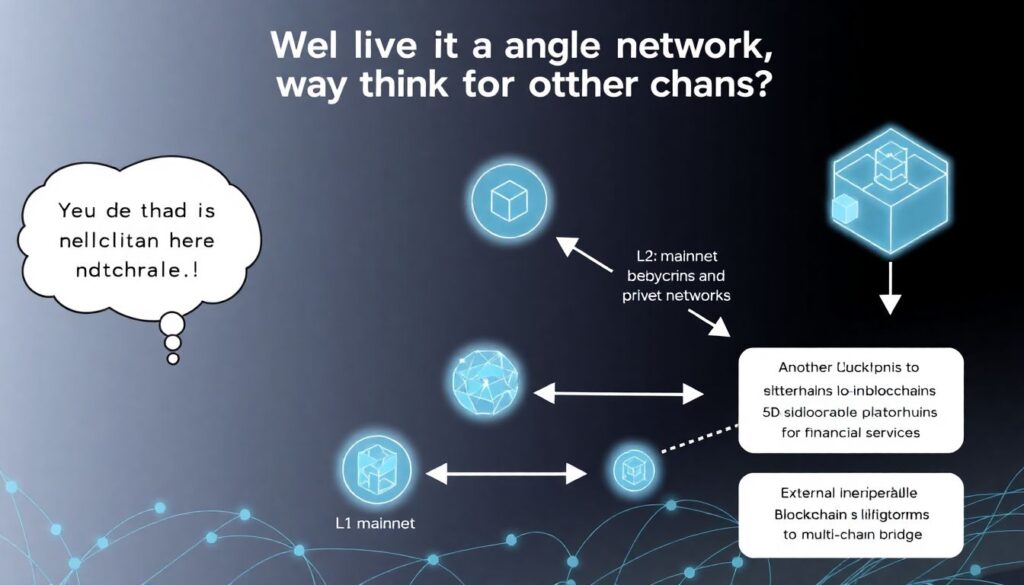
Новички часто думают: «Мы же живём в одной сети, зачем думать про другие цепочки?».
Проблема в том, что через полгода приходит задача интегрироваться:
– с другим блокчейном (L2, сайдчейн, приватная сеть)
– с внешней interoperable blockchain AI platforms for financial services
– с кроссчейн‑мостом или провайдером данных
И тут вылезает суровая правда: без cross-chain data standardization tools for AI and blockchain начинаются бесконечные конвертеры, ручные маппинги и боли с валидацией.
Как избежать:
– заранее продумать, как твои сущности будут выглядеть в другой цепочке
– не привязывать формат данных жёстко к конкретному блокчейну (выносить бизнес‑сущности на уровень схем)
– использовать нейтральные форматы и явные маппинги между сетями
—
Ошибка №3: Пытаться пихнуть ВСЕ данные on-chain
«Нам нужна прозрачность, всё на блокчейн!» — ещё одна классика.
В итоге:
– огромные транзакции
– дикие комиссии
– ограничения по размеру данных
– проблемы с приватностью и правом на удаление (привет, GDPR)
AI‑модели обычно хотят богатые, сырые, контекстные данные. А блокчейн хорош для:
– хэшей и доказательств целостности
– ссылок на внешнее хранилище
– агрегированных/обработанных данных
– важнейших событий (триггеров) для обучения или inference
Глубокие датасеты и логи логичнее держать off-chain, связав их с on-chain событиями через стандартизированные идентификаторы и криптографические доказательства.
—
Ошибка №4: Игнорирование метаданных и контекста
Новички часто логируют только «что произошло», а не «в каких условиях и по каким правилам».
Для AI это критично: две одинаковые транзакции в разных регуляторных зонах или под разными пользовательскими согласиями — это разные случаи.
Нужно явно стандартизировать метаданные:
– юрисдикция
– версия смарт‑контракта
– политика приватности, действующая в момент события
– источник данных (человек, IoT, сервис, оракул)
– степень доверия к источнику
Без этого любая аналитика становится опасным приближением.
—
Из чего состоит практический стандарт данных для AI на блокчейне
Слой сущностей и терминов
Сначала договариваемся о словах. Это звучит банально, но именно тут чаще всего всё ломается.
Полезно описать:
– ключевые бизнес‑сущности (пользователь, аккаунт, транзакция, сессия, актив и т.п.)
– их связи: кто чей родитель, что от чего зависит
– обязательные и опциональные поля
– допустимые значения и диапазоны
Совет: делай это не в голове и не в презентации, а в виде машинно‑читаемых схем, которые можно автоматически проверять.
—
Слой форматов и сериализации
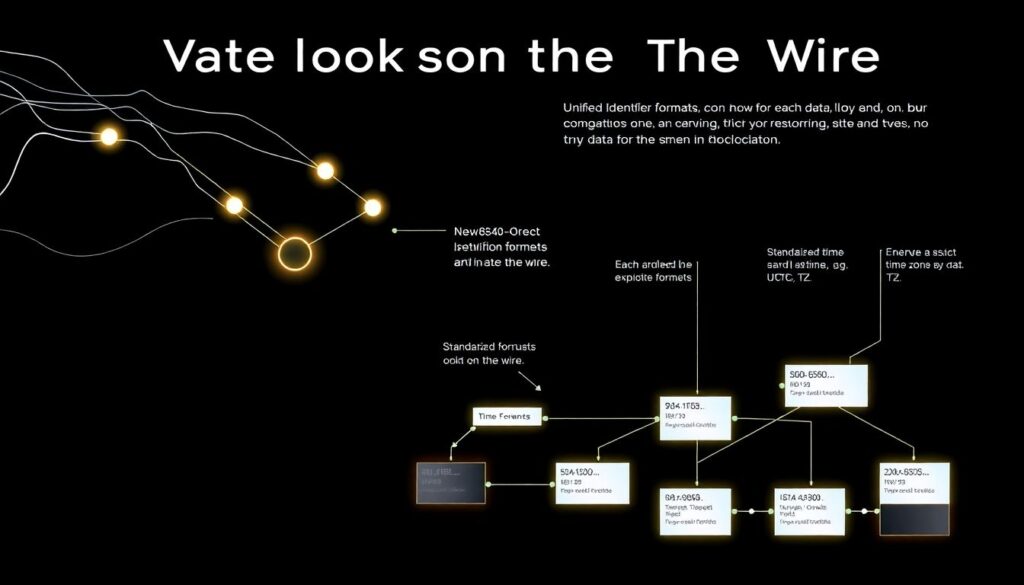
Дальше — как именно данные выглядят «на проводе» и в блокчейне.
Обрати внимание на:
– единый формат идентификаторов (UUID, hex, bech32 и т.п.)
– стандартизированный формат времени (ISO 8601, Unix time с явным указанием TZ)
– кодировки и локали (не смешивать в одном поле несколько языков и форматов)
– версионирование схем: `schema_version`, `data_version`, `contract_version`
Тогда AI‑сервисы могут однозначно понимать, с чем имеют дело, и как интерпретировать значения.
—
Слой доступа и разрешений
AI часто работает с чувствительной информацией. В enterprise‑контексте, особенно когда строятся interoperable blockchain AI platforms for financial services, вопросы доступа убивают больше проектов, чем баги в коде.
Важно:
– явно прописать, какие поля доступны:
– публично
– по токену доступа
– внутри ограниченного контура (KYC, AML, внутренняя аналитика)
– использовать унифицированную модель прав (RBAC, ABAC) для AI‑сервисов
– логировать сам факт доступа AI‑модели к данным (кто, когда, по какому запросу)
—
Как подружить несколько блокчейнов и AI в одном стеке
Если у тебя один блокчейн и одна модель — тебе повезло. Но реальность чаще такая:
несколько сетей, несколько AI‑сервисов, куча внешних оракулов и аналитических платформ.
Чтобы это не развалилось, нужны продуманные AI data interoperability solutions for blockchain networks:
– Единые схемы данных: один «язык» сущностей поверх всех цепочек
– Канонические идентификаторы: пользователь/актив имеет глобальный ID, а не 5 разных
– Сервис трансформаций: явные, документированные правила, как данные из сети A превращаются в формат сети B
– Слой валидации: каждый новый источник данных проверяется на соответствие стандарту перед тем, как попасть в общий даталейк или модель
—
Практические советы, чтобы не угробить проект на старте
1. Начни с минимального, но чёткого стандарта
Не нужно сразу писать «идеальный» мегастандарт на 200 страниц.
Сконцентрируйся на базовом:
– Унифицированные идентификаторы
– Формат времени и валюты/актива
– Структура событий (кто, что, когда, результат, контекст)
– Минимальный набор метаданных (юрисдикция, источник, версия контракта)
Важно, чтобы все участники проекта реально этим пользовались.
—
2. Заставь смарт‑контракты говорить на одном языке
Когда проект растёт, появляются новые контракты от разных команд. Если не ввести правила, каждый будет «изобретать свои названия полей».
Полезные приёмы:
– библиотека общих структур и событий, которую импортируют все контракты
– чек‑лист для ревью: нельзя деплоить контракт, который не следует стандарту
– автогенерация документации из схем и событий, а не вручную
—
3. Обязательно думай про off-chain ещё в начале
AI почти всегда будет жадным до данных: логи, поведение, фичи, результаты inference, A/B‑тесты, обратная связь.
Заранее спроектируй связку:
– что хранится on-chain (события, хэши, ключевые агрегаты)
– что хранится off-chain (детальки, сырые логи, фичи)
– как они связаны (ID, хэши, подписи, ссылки)
– как AI‑модель валидирует, что off-chain данные не подменены (проверка хэшей, меркл‑доказательства и т.д.)
—
4. Не забывай про эволюцию схем
Данные для AI редко остаются неизменными: появляются новые фичи, поля, сущности.
Чтобы не убить совместимость:
– всегда добавляй `schema_version`
– не ломай старые поля без крайней необходимости
– документируй правила миграции (как `v1` превращается в `v2`)
– тестируй новые версии на куске реальных данных и против старых моделей
—
На что смотреть при выборе инструментов и платформ
Когда ты подбираешь инструменты для blockchain-based data infrastructure for AI applications, обрати внимание не только на маркетинг и громкие слова «AI-ready», а на конкретику.
Полезные признаки:
– поддержка явных схем данных и их валидации
– нормальная работа с несколькими блокчейнами (L1, L2, приватные сети)
– встроенные механизмы версионирования данных и контрактов
– понятные API для AI‑сервисов (streaming, batch, подписки на события)
– возможность внедрить свои правила безопасности и комплаенса
Не стесняйся задавать платформам прямые вопросы:
«Как у вас реализована data interoperability между сетями?» и «Что произойдёт, если я изменю схему через полгода?».
—
Итоги: стандарты данных — это не бюрократия, а страховка от хаоса
Интероперабельные стандарты данных для AI на блокчейнах — это не про «ещё один документ ради галочки». Это:
– способ быстро подключать новые источники и модели
– защита от бесконечных ручных маппингов и конвертеров
– основа для кроссчейн‑аналитики и доверия к результатам AI
– необходимое условие, чтобы enterprise blockchain data standards for AI integration не превращались в маркетинговый слоган
Новички чаще всего ошибаются в одном: откладывают разговор про стандарты «на потом».
Рабочий подход обратный: сначала общий язык данных, потом контракты и модели.
Тогда и AI, и блокчейн начинают работать в одной команде, а не тянуть проект в разные стороны.